AInnouncer Studio
Project start: June 2025 — Present
Role: Tech Lead / AI Engineer
Status: 🟢 Active Development
Project description
AInnouncer Studio is a comprehensive AI platform for automatic audio content generation for radio stations, built on a professional LLMs and LLOps architecture.
Radio stations need regular, professional audio content: weather forecasts, music announcements, on-air messages, or advertising materials. This process is time-consuming, expensive, difficult to scale, and heavily dependent on people.
The system combines:
- text generation (LLM),
- voice synthesis (TTS),
- audio mixing (broadcast-ready),
- automation,
- monitoring and quality control.
The platform was designed as a scalable SaaS, ready for multiple clients and additional modules.
Architecture Overview
AInnouncer Studio is an event-driven + worker-based architecture:
- Frontend (Next.js) — configuration of modules, prompts, voices, schedules
- Backend API (FastAPI) — domain logic, routing, validation, orchestration
- Asynchronous workers (Dramatiq + Redis) — content generation, TTS, mixing, upload
- LLM Layer — OpenAI GPT-4o / GPT-4o-mini with advanced system prompts
- LLOps & Observability — Langfuse (traces, spans, cost, quality), prompt versioning, Promptfoo (prompt testing)
- Data Layer — PostgreSQL (configurations, prompts, voices, schedules), S3-compatible storage (audio)
- Infrastructure — Docker Compose, CI/CD, Monitoring (Prometheus + Grafana)
Key Modules
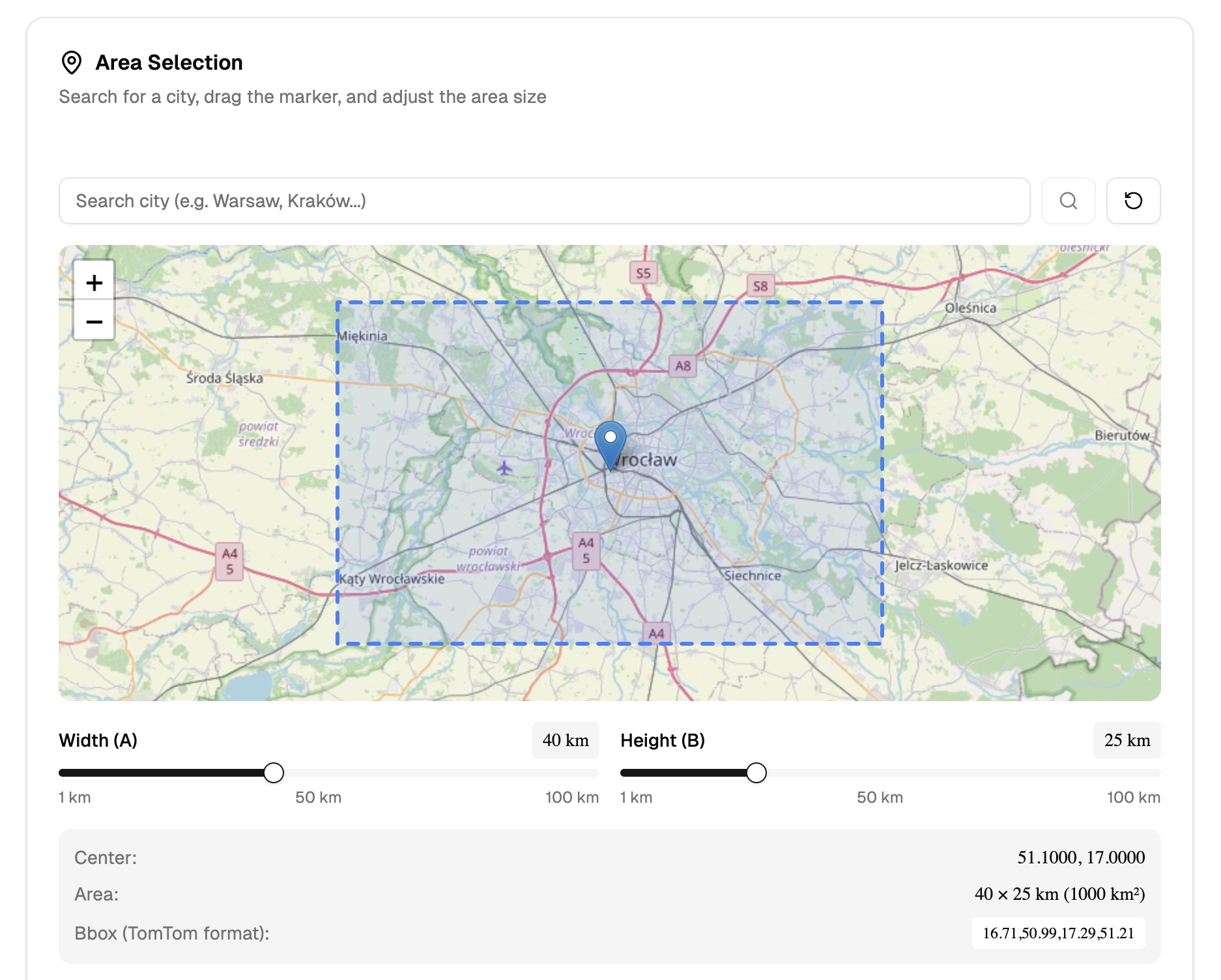
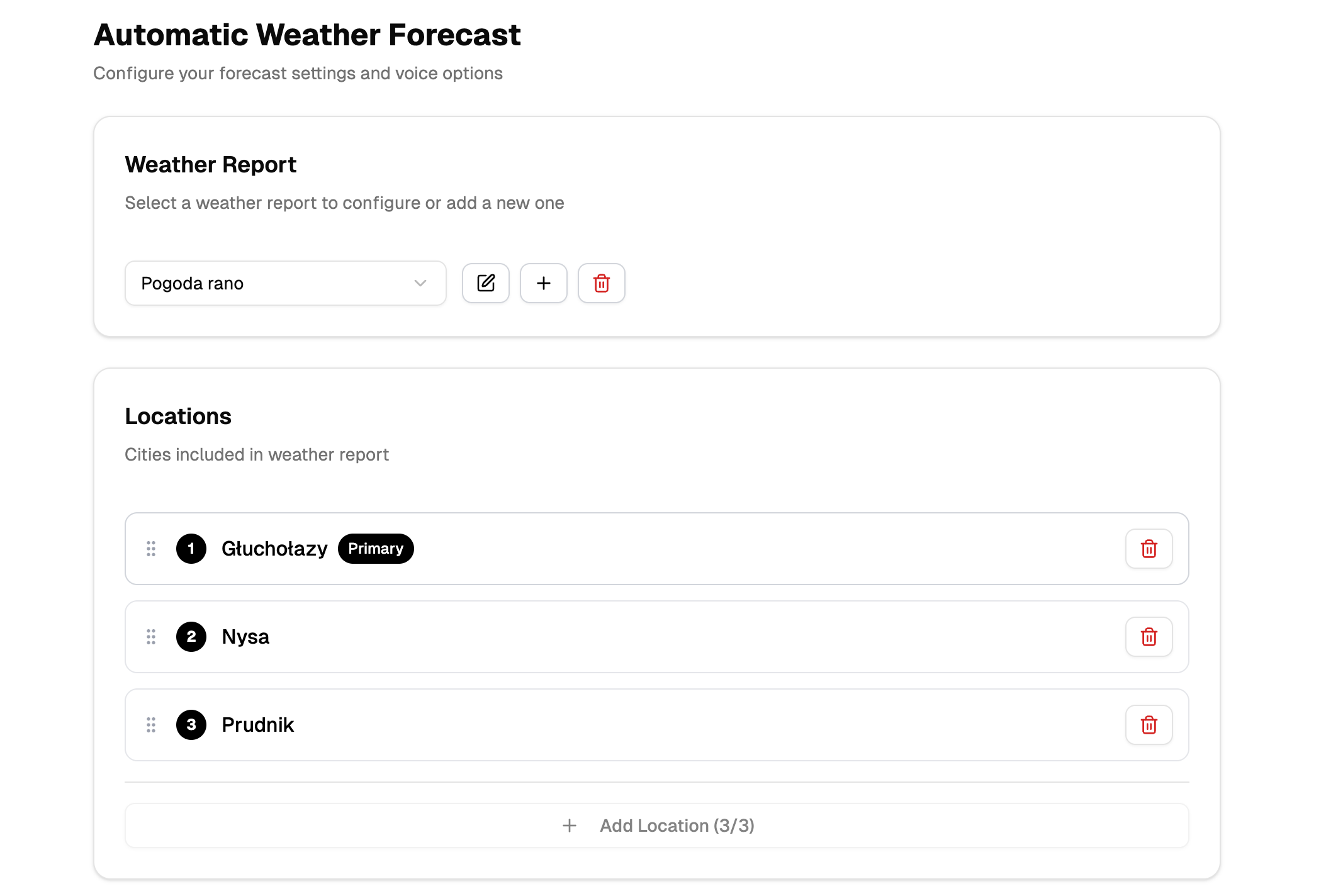
Weather Forecast (Production)
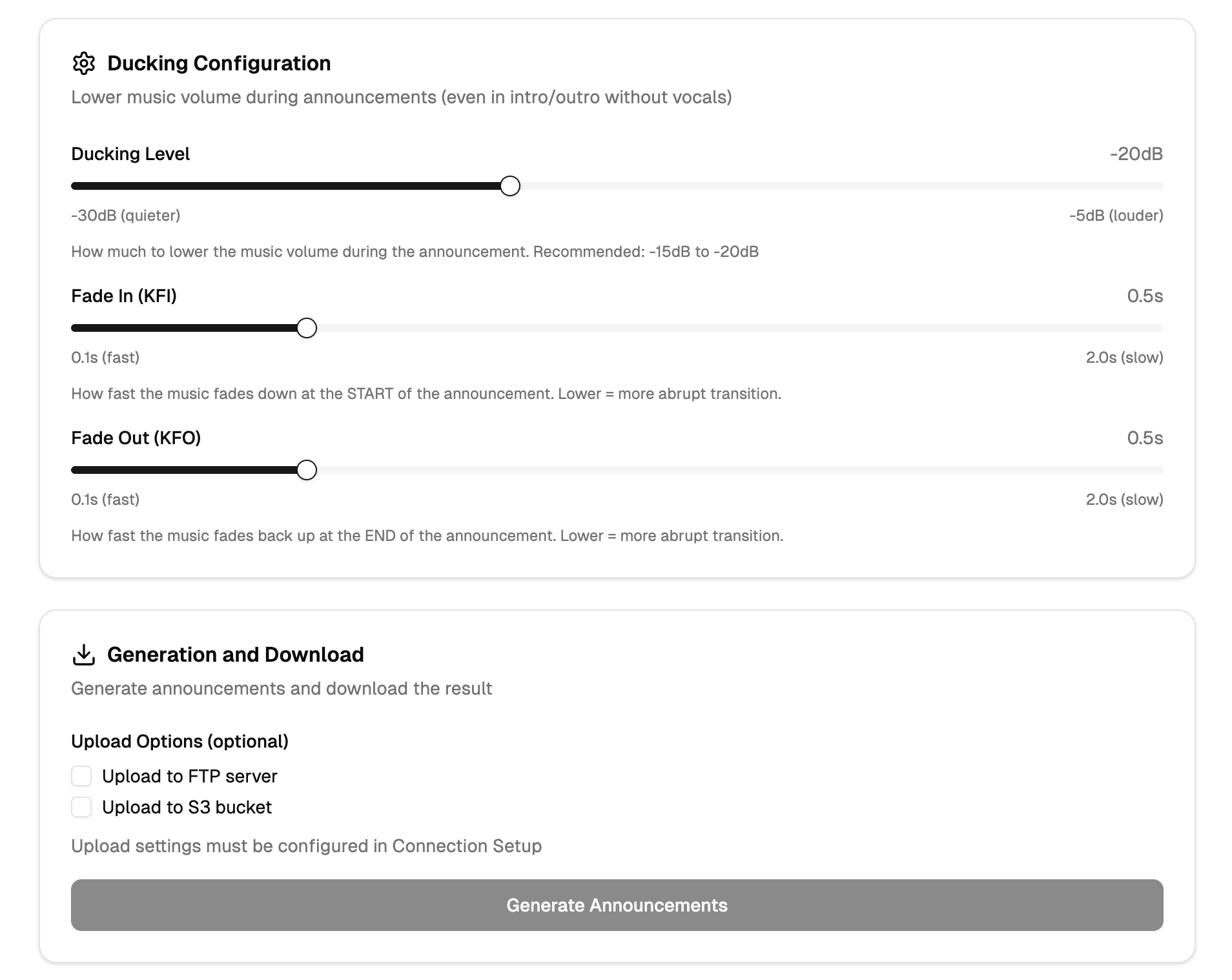
- weather data → LLM text → TTS voice → jingle mix → upload
- support for multiple locations and languages
- broadcast schedules
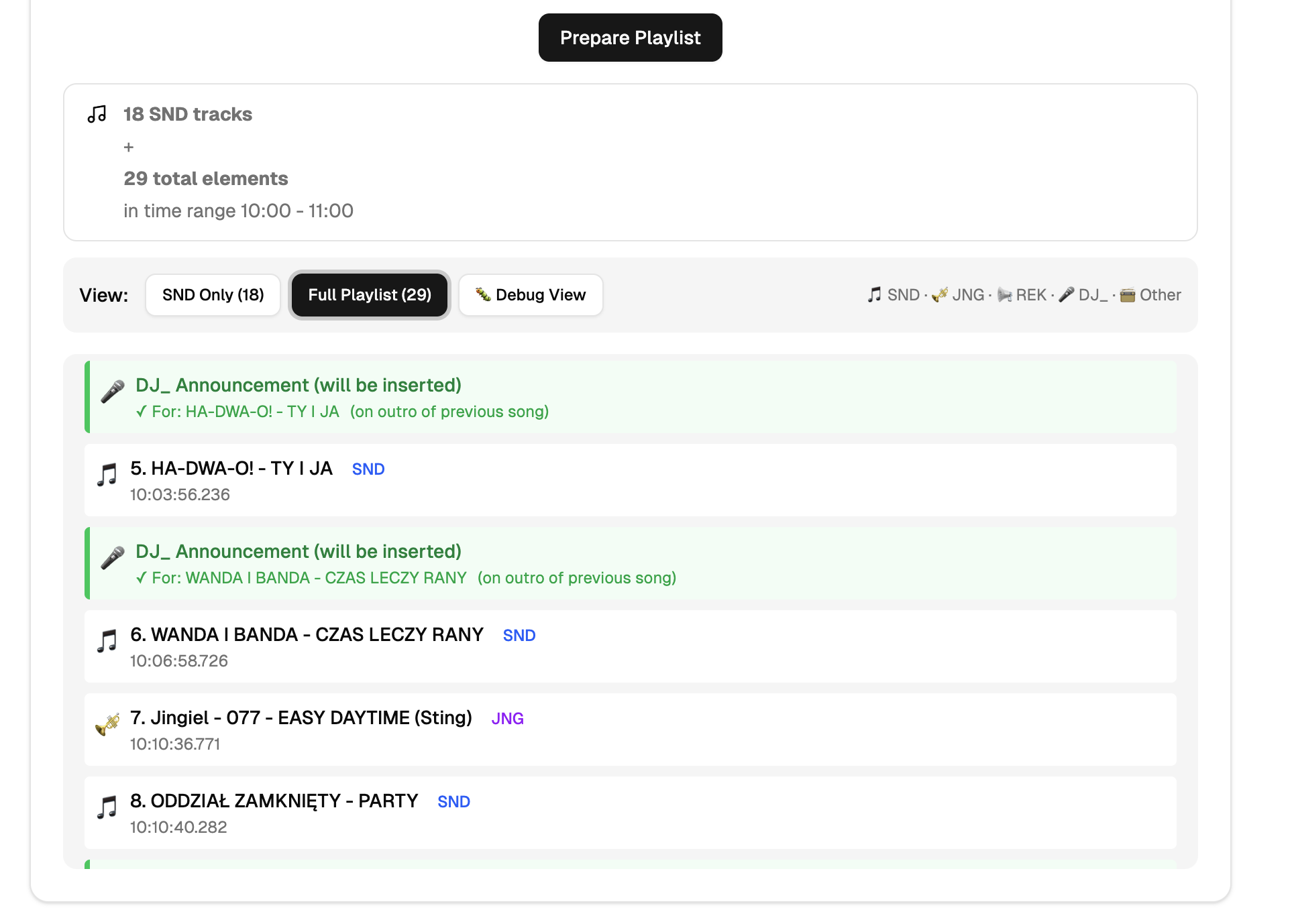
AInnouncer (DJ / Music Announcer)
- playlist parsing (.mix)
- batch text generation
- announcement frequency control
- audio ready for broadcast automation
Platform Core (LLOps)
- prompt versioning
- response quality monitoring
- LLM cost analysis
- retry & fallback logic
- preparation for AI agents
What I did
- Designed the complete AI system architecture in production
- Built the backend in FastAPI with separation of concerns
- Implemented asynchronous pipelines (Dramatiq)
- Created the LLM layer with prompt control and validation
- Integrated Langfuse for LLM observability and monitoring
- Deployed Promptfoo for prompt testing
- Built TTS and audio mixing system to radio standards
- Designed CI/CD and cloud environment
- Prepared the platform for further AI agent development
Skills
- Python
- FastAPI
- OpenAI GPT-4o
- ElevenLabs TTS
- Langfuse
- Promptfoo
- PostgreSQL
- Redis
- Dramatiq
- Docker
- DigitalOcean
- Next.js
- TypeScript
- Prometheus
- Grafana
Results
- Fully automatic generation of broadcast-ready audio content
- Stable, production AI architecture (not a demo)
- Full control over LLM quality and costs
- System ready to scale as a SaaS product
- Solid foundation for:
- AI agents
- additional modules (ads, traffic, voice branding)
- international expansion
Sample photos