AInnouncer Studio
Start projektu: czerwiec 2025 — obecnie
Rola: Tech Lead / AI Engineer
Status: 🟢 Akrywny rozwój
Opis projektu
AInnouncer Studio to kompleksowa platforma AI do automatycznego generowania treści audio dla stacji radiowych, zbudowana na profesjonalnej architekturze LLMs i LLOps.
Stacje radiowe potrzebują regularnych, profesjonalnych treści audio: prognoz pogody, zapowiedzi muzycznych, komunikatów antenowych czy materiałów reklamowych. Proces ten jest czasochłonny, kosztowny, trudny do skalowania i silnie zależny od ludzi.
System łączy:
- generowanie tekstu (LLM),
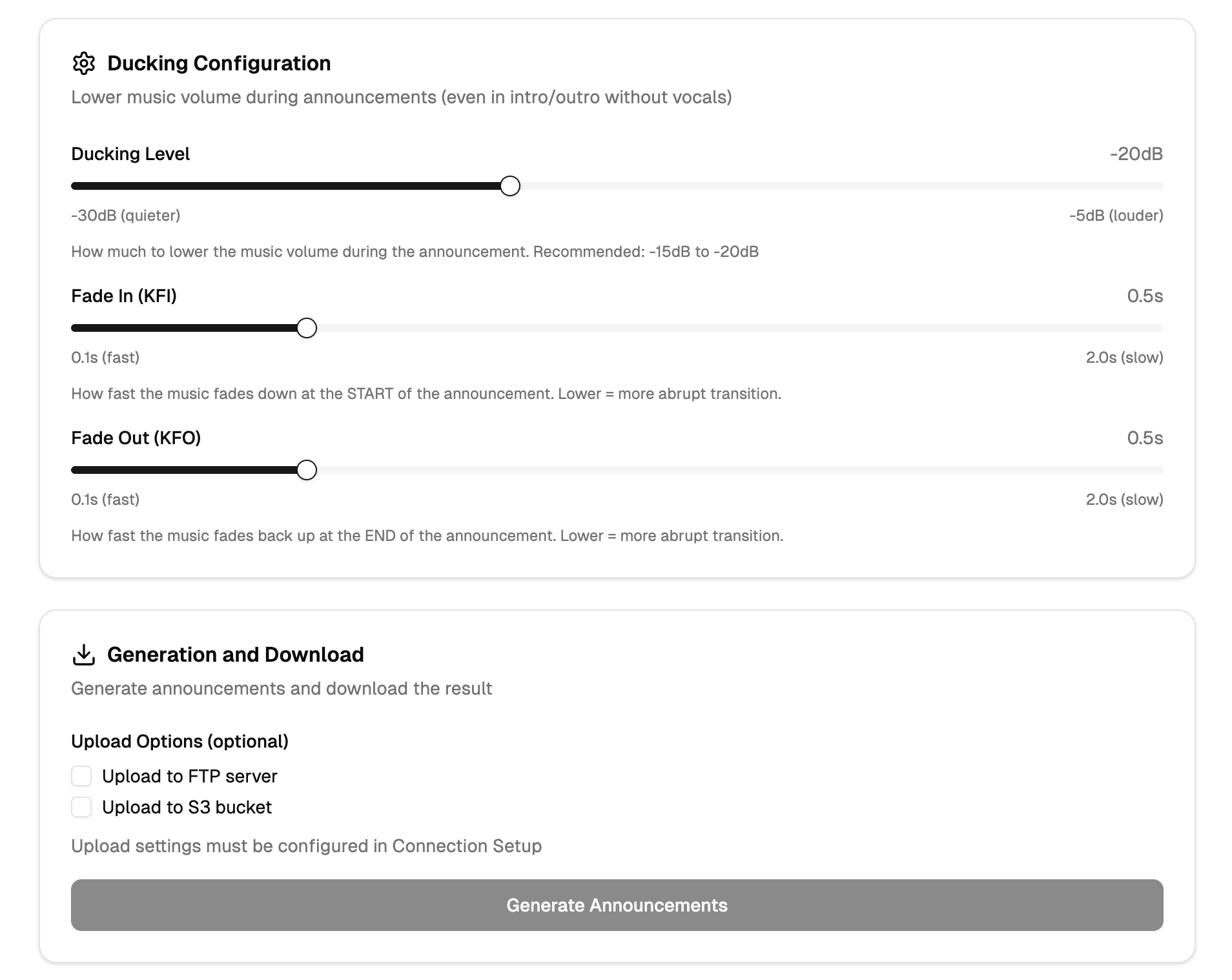
- syntezę mowy (TTS),
- miksowanie audio (broadcast-ready),
- automatyzację,
- monitoring i kontrolę jakości.
Platforma została zaprojektowana jako skalowalny SaaS, gotowy na wielu klientów i dodatkowe moduły.
Architektura
AInnouncer Studio to architektura event-driven + worker-based:
- Frontend (Next.js) — konfiguracja modułów, promptów, głosów, harmonogramów
- Backend API (FastAPI) — logika domenowa, routing, walidacja, orchestracja
- Asynchroniczni workerzy (Dramatiq + Redis) — generowanie treści, TTS, miksowanie, upload
- Warstwa LLM — OpenAI GPT-4o / GPT-4o-mini z zaawansowanymi promptami systemowymi
- LLOps & Observability — Langfuse (traces, spans, koszt, jakość), wersjonowanie promptów, Promptfoo (testy promptów)
- Warstwa danych — PostgreSQL (konfiguracje, prompty, głosy, harmonogramy), storage S3-compatible (audio)
- Infrastruktura — Docker Compose, CI/CD, Monitoring (Prometheus + Grafana)
Kluczowe moduły
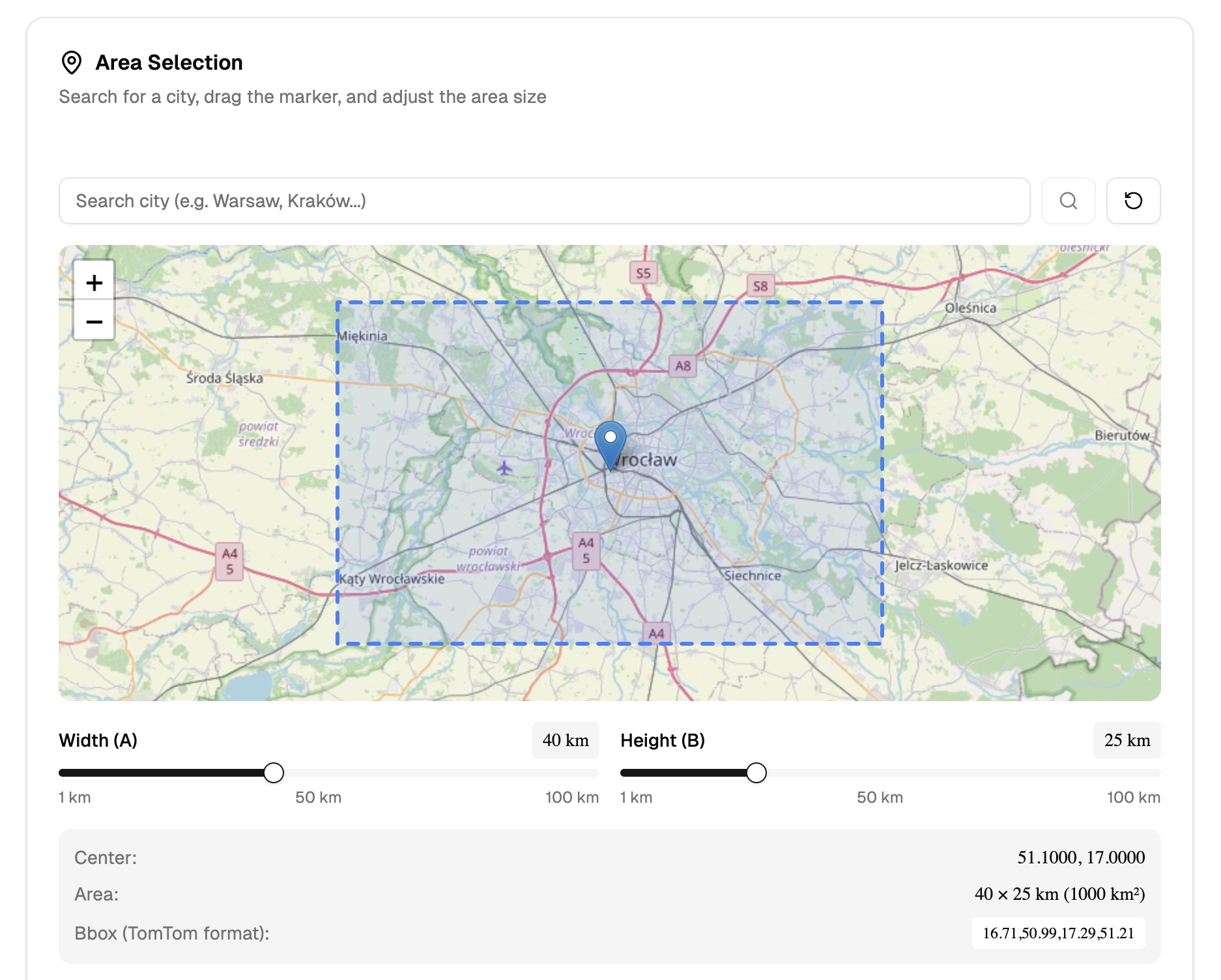
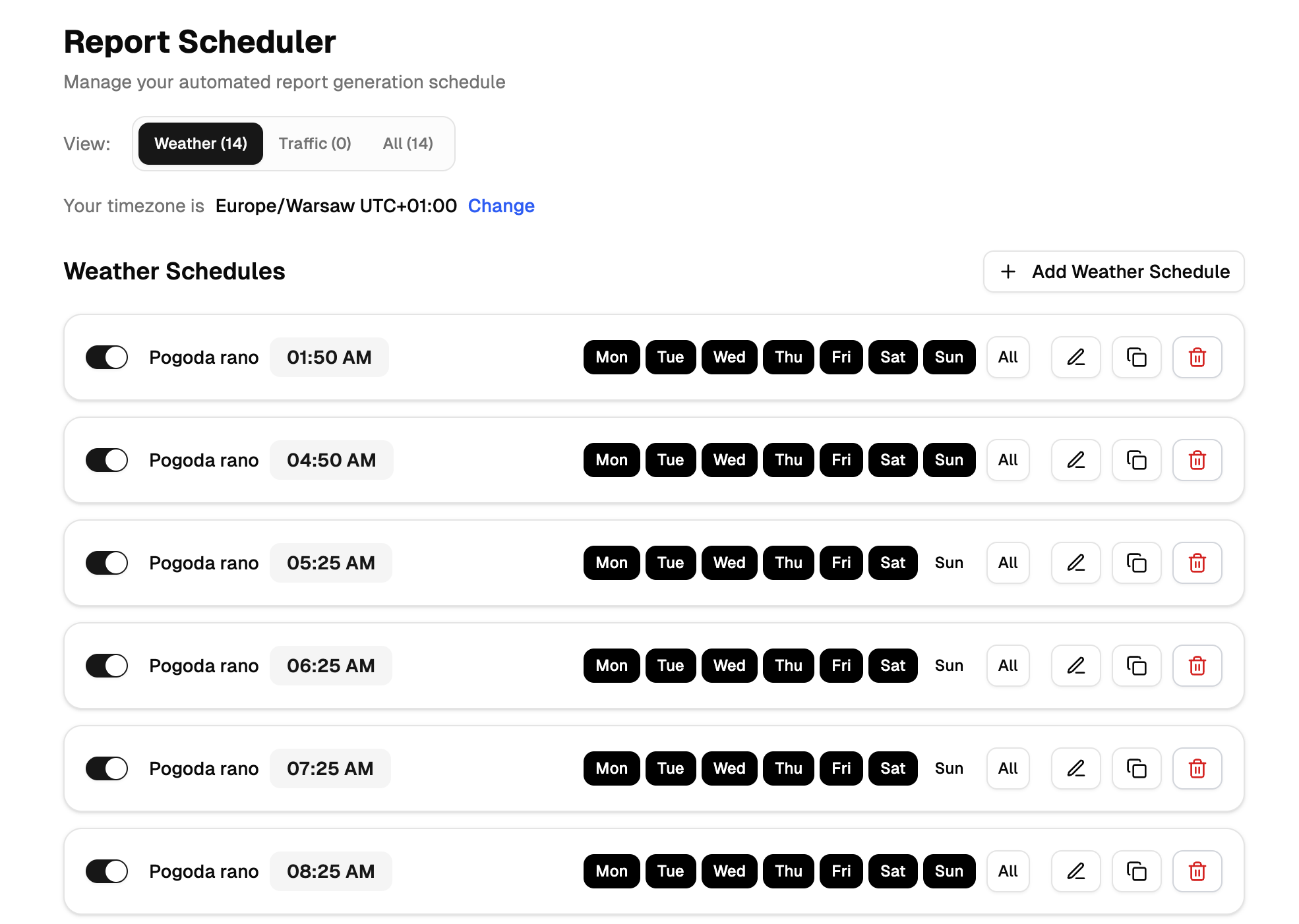
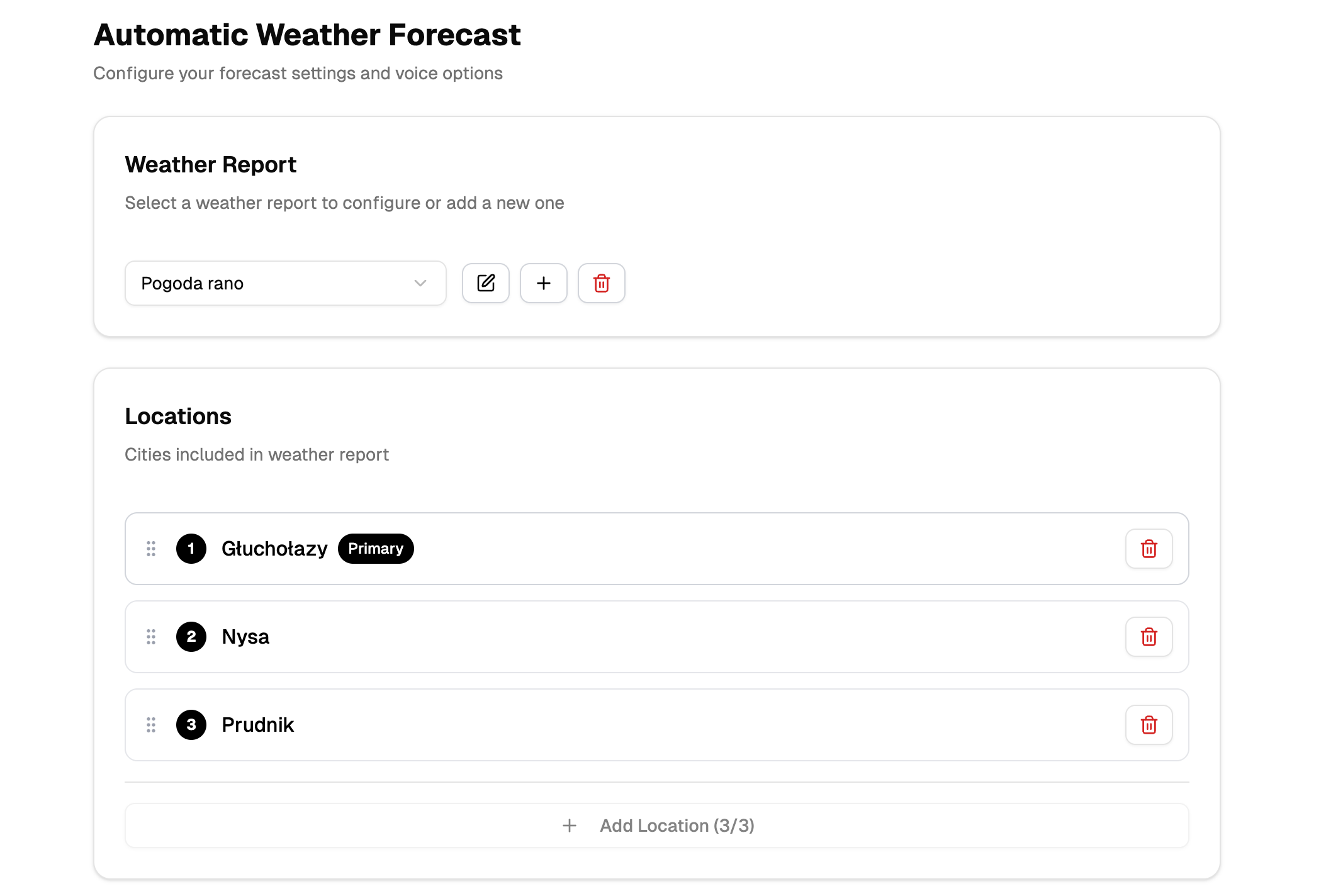
Prognoza pogody (Produkcja)
- dane pogodowe → tekst LLM → głos TTS → miks z jinglem → upload
- obsługa wielu lokalizacji i języków
- harmonogramy emisji
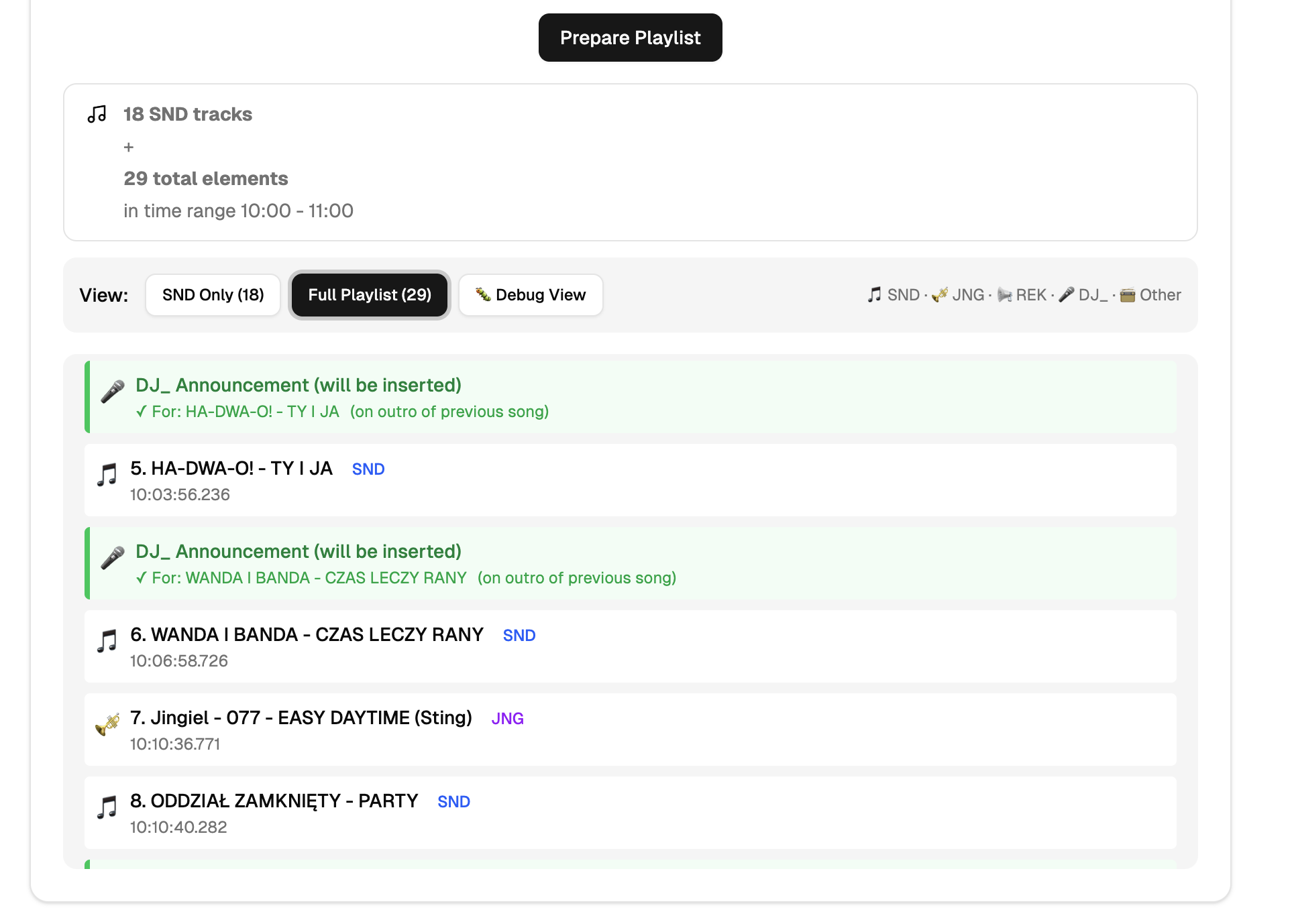
AInnouncer (DJ / Zapowiedzi muzyczne)
- parsowanie playlist (.mix)
- batchowe generowanie tekstów
- kontrola częstotliwości zapowiedzi
- audio gotowe do wpięcia w automat emisyjny
Platform Core (LLOps)
- wersjonowanie promptów
- monitoring jakości odpowiedzi
- analiza kosztów LLM
- retry & fallback logic
- przygotowanie pod agentów AI
Co zrobiłem
- Zaprojektowałem pełną architekturę systemu AI w produkcji
- Zbudowałem backend w FastAPI z rozdzieleniem odpowiedzialności
- Zaimplementowałem asynchroniczne pipeline'y (Dramatiq)
- Stworzyłem warstwę LLM z kontrolą promptów i walidacją
- Zintegrowałem Langfuse do observability i monitoringu LLM
- Wdrożyłem Promptfoo do testowania promptów
- Zbudowałem system TTS i miksowania audio pod standardy radiowe
- Zaprojektowałem CI/CD oraz środowisko chmurowe
- Przygotowałem platformę pod dalszy rozwój agentów AI
Umiejętności
- Python
- FastAPI
- OpenAI GPT-4o
- ElevenLabs TTS
- Langfuse
- Promptfoo
- PostgreSQL
- Redis
- Dramatiq
- Docker
- DigitalOcean
- Next.js
- TypeScript
- Prometheus
- Grafana
Rezultaty
- W pełni automatyczne generowanie treści audio gotowych do emisji
- Stabilna, produkcyjna architektura AI (nie demo)
- Pełna kontrola nad jakością i kosztami LLM
- System gotowy do skalowania jako produkt SaaS
- Solidna baza pod:
- agentów AI
- kolejne moduły (reklamy, traffic, voice branding)
- ekspansję międzynarodową
Zdjęcia