import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
# Tworzenie realistycznych danych produktów
np.random.seed(42)
n_products = 2000
data = pd.DataFrame({
'cena': np.random.lognormal(6, 1, n_products), # log-normal dla cen
'jakosc': np.random.randint(1, 11, n_products), # 1-10 skala jakości
'marketing_budget': np.random.exponential(50000, n_products),
'konkurencja': np.random.randint(1, 21, n_products), # liczba konkurentów
'sezon': np.random.choice(['wiosna', 'lato', 'jesien', 'zima'], n_products),
'kategoria': np.random.choice(['elektronika', 'moda', 'dom', 'sport', 'ksiazki'], n_products),
'ocena_testowa': np.random.normal(7, 2, n_products), # oceny focus group
'innowacyjnosc': np.random.randint(1, 11, n_products),
'marka_znana': np.random.choice([0, 1], n_products, p=[0.3, 0.7]) # czy znana marka
})
# Realistyczna logika sukcesu produktu
def czy_sukces(row):
score = 0
# Cena (sweet spot 50-500)
if 50 <= row['cena'] <= 500:
score += 2
elif row['cena'] > 1000:
score -= 2
# Jakość (najważniejsze!)
score += row['jakosc'] * 0.8
# Marketing
if row['marketing_budget'] > 100000:
score += 3
elif row['marketing_budget'] > 50000:
score += 1
# Konkurencja (mniej = lepiej)
score -= row['konkurencja'] * 0.2
# Sezon (lato i zima lepsze)
if row['sezon'] in ['lato', 'zima']:
score += 1
# Kategoria
if row['kategoria'] == 'elektronika':
score += 1
elif row['kategoria'] == 'ksiazki':
score -= 1
# Ocena testowa
score += (row['ocena_testowa'] - 5) * 0.5
# Innowacyjność
score += row['innowacyjnosc'] * 0.3
# Znana marka
if row['marka_znana']:
score += 2
# Końcowa decyzja z odrobiną losowości
probability = 1 / (1 + np.exp(-score + np.random.normal(0, 1)))
return probability > 0.5
data['sukces'] = data.apply(czy_sukces, axis=1)
print("Statystyki produktów:")
print(data.describe())
print(f"\nOdsetek udanych produktów: {data['sukces'].mean():.1%}")Random Forest — las drzew decyzyjnych
🌲 Czym jest Random Forest?
Random Forest to zespół wielu drzew decyzyjnych, które głosują razem nad końcową decyzją. Jeden Decision Tree może się mylić, ale gdy masz 100 drzew i większość mówi “TAK” - to prawdopodobnie dobra odpowiedź!
💡 Intuicja
Wyobraź sobie konsylium lekarskim: jeden lekarz może się pomylić w diagnozie, ale gdy 7 z 10 ekspertów zgadza się - diagnoza jest znacznie bardziej pewna. Random Forest działa dokładnie tak samo!
🎯 Praktyczny przykład: przewidywanie sukcesu produktu
Czy nowy produkt odniesie sukces na rynku?
Pokaż statystyki produktów
Statystyki produktów:
cena jakosc marketing_budget konkurencja \
count 2000.000000 2000.000000 2000.000000 2000.00000
mean 692.530569 5.534500 49376.934612 10.53950
std 929.701850 2.871922 49876.166534 5.76594
min 15.779832 1.000000 11.353200 1.00000
25% 216.445352 3.000000 13957.783468 6.00000
50% 421.867820 6.000000 33526.684882 11.00000
75% 798.695019 8.000000 67692.822351 16.00000
max 19010.210160 10.000000 376260.171802 20.00000
ocena_testowa innowacyjnosc marka_znana
count 2000.000000 2000.000000 2000.000000
mean 7.011461 5.500000 0.711000
std 1.957420 2.909679 0.453411
min -0.844801 1.000000 0.000000
25% 5.700781 3.000000 0.000000
50% 7.041344 6.000000 1.000000
75% 8.307413 8.000000 1.000000
max 13.754766 10.000000 1.000000
Odsetek udanych produktów: 99.2%🔧 Budowanie modelu krok po kroku
1) Przygotowanie danych
# Encoding kategorycznych zmiennych
from sklearn.preprocessing import LabelEncoder
data_encoded = data.copy()
le_sezon = LabelEncoder()
le_kategoria = LabelEncoder()
data_encoded['sezon_num'] = le_sezon.fit_transform(data['sezon'])
data_encoded['kategoria_num'] = le_kategoria.fit_transform(data['kategoria'])
# Features do modelu
feature_columns = ['cena', 'jakosc', 'marketing_budget', 'konkurencja',
'sezon_num', 'kategoria_num', 'ocena_testowa',
'innowacyjnosc', 'marka_znana']
X = data_encoded[feature_columns]
y = data_encoded['sukces']
# Podział train/test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print(f"Dane treningowe: {len(X_train)} produktów")
print(f"Dane testowe: {len(X_test)} produktów")
Pokaż podział danych
Dane treningowe: 1600 produktów
Dane testowe: 400 produktów2) Trenowanie Random Forest
# Tworzenie modelu Random Forest
rf_model = RandomForestClassifier(
n_estimators=100, # liczba drzew w lesie
max_depth=10, # maksymalna głębokość każdego drzewa
min_samples_split=20, # min. próbek do podziału
min_samples_leaf=10, # min. próbek w liściu
random_state=42,
n_jobs=-1 # użyj wszystkie rdzenie CPU
)
# Trenowanie
rf_model.fit(X_train, y_train)
print("Random Forest wytrenowany!")
print(f"Liczba drzew: {rf_model.n_estimators}")
print(f"Średnia głębokość drzew: {np.mean([tree.tree_.max_depth for tree in rf_model.estimators_]):.1f}")
Pokaż parametry wytrenowanego modelu
Random Forest wytrenowany!
Liczba drzew: 100
Średnia głębokość drzew: 5.23) Ewaluacja modelu
# Predykcje
y_pred = rf_model.predict(X_test)
y_pred_proba = rf_model.predict_proba(X_test)[:, 1]
# Metryki
accuracy = accuracy_score(y_test, y_pred)
print(f"\nDokładność Random Forest: {accuracy:.1%}")
# Szczegółowy raport
print("\nRaport klasyfikacji:")
print(classification_report(y_test, y_pred))
# Confusion Matrix
cm = confusion_matrix(y_test, y_pred)
print("\nConfusion Matrix:")
print("Przewidywane: Porażka Sukces")
print(f"Rzeczywiste Porażka: {cm[0,0]:3d} {cm[0,1]:3d}")
print(f"Rzeczywiste Sukces: {cm[1,0]:3d} {cm[1,1]:3d}")
Pokaż wyniki Random Forest
Dokładność Random Forest: 99.8%
Confusion Matrix:
Przewidywane: Porażka Sukces
Rzeczywiste Porażka: 0 1
Rzeczywiste Sukces: 0 399📊 Analiza ważności cech (Feature Importance)
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
import matplotlib.pyplot as plt
# Przygotuj dane (powtarzamy dla kompletności)
np.random.seed(42)
n_products = 2000
data = pd.DataFrame({
'cena': np.random.lognormal(6, 1, n_products),
'jakosc': np.random.randint(1, 11, n_products),
'marketing_budget': np.random.exponential(50000, n_products),
'konkurencja': np.random.randint(1, 21, n_products),
'sezon': np.random.choice(['wiosna', 'lato', 'jesien', 'zima'], n_products),
'kategoria': np.random.choice(['elektronika', 'moda', 'dom', 'sport', 'ksiazki'], n_products),
'ocena_testowa': np.random.normal(7, 2, n_products),
'innowacyjnosc': np.random.randint(1, 11, n_products),
'marka_znana': np.random.choice([0, 1], n_products, p=[0.3, 0.7])
})
def czy_sukces(row):
score = 0
if 50 <= row['cena'] <= 500:
score += 2
elif row['cena'] > 1000:
score -= 2
score += row['jakosc'] * 0.8
if row['marketing_budget'] > 100000:
score += 3
elif row['marketing_budget'] > 50000:
score += 1
score -= row['konkurencja'] * 0.2
if row['sezon'] in ['lato', 'zima']:
score += 1
if row['kategoria'] == 'elektronika':
score += 1
elif row['kategoria'] == 'ksiazki':
score -= 1
score += (row['ocena_testowa'] - 5) * 0.5
score += row['innowacyjnosc'] * 0.3
if row['marka_znana']:
score += 2
probability = 1 / (1 + np.exp(-score + np.random.normal(0, 1)))
return probability > 0.5
data['sukces'] = data.apply(czy_sukces, axis=1)
# Encoding i model
data_encoded = data.copy()
le_sezon = LabelEncoder()
le_kategoria = LabelEncoder()
data_encoded['sezon_num'] = le_sezon.fit_transform(data['sezon'])
data_encoded['kategoria_num'] = le_kategoria.fit_transform(data['kategoria'])
feature_columns = ['cena', 'jakosc', 'marketing_budget', 'konkurencja',
'sezon_num', 'kategoria_num', 'ocena_testowa',
'innowacyjnosc', 'marka_znana']
X = data_encoded[feature_columns]
y = data_encoded['sukces']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Trenuj model
rf_model = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42, n_jobs=-1)
rf_model.fit(X_train, y_train)
# Ewaluacja
y_pred = rf_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
# Ważność cech
feature_names = ['cena', 'jakość', 'marketing_budget', 'konkurencja',
'sezon', 'kategoria', 'ocena_testowa', 'innowacyjność', 'marka_znana']
importance = rf_model.feature_importances_
feature_importance = pd.DataFrame({
'feature': feature_names,
'importance': importance
}).sort_values('importance', ascending=False)
# Wykres ważności cech
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'], feature_importance['importance'])
plt.xlabel('Ważność cechy')
plt.title('Ważność cech w przewidywaniu sukcesu produktu')
plt.gca().invert_yaxis()
plt.close()
print(f"Wyniki Random Forest:")
print(f"Dokładność modelu: {accuracy:.1%}")
print(f"Liczba drzew: {rf_model.n_estimators}")
print("\nConfusion Matrix:")
print("Przewidywane: Porażka Sukces")
print(f"Rzeczywiste Porażka: {cm[0,0]:3d} {cm[0,1]:3d}")
print(f"Rzeczywiste Sukces: {cm[1,0]:3d} {cm[1,1]:3d}")
print("\nWażność cech:")
for _, row in feature_importance.iterrows():
print(f"{row['feature']}: {row['importance']:.3f}")
# Odtwórz wykres
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'], feature_importance['importance'])
plt.xlabel('Ważność cechy')
plt.title('Ważność cech w przewidywaniu sukcesu produktu')
plt.gca().invert_yaxis()
plt.show()
Pokaż wyniki i wykres ważności cech
Wyniki Random Forest:
Dokładność modelu: 99.8%
Liczba drzew: 100
Confusion Matrix:
Przewidywane: Porażka Sukces
Rzeczywiste Porażka: 0 1
Rzeczywiste Sukces: 0 399
Ważność cech:
cena: 0.294
marketing_budget: 0.168
ocena_testowa: 0.143
jakość: 0.117
konkurencja: 0.105
innowacyjność: 0.069
sezon: 0.042
kategoria: 0.033
marka_znana: 0.028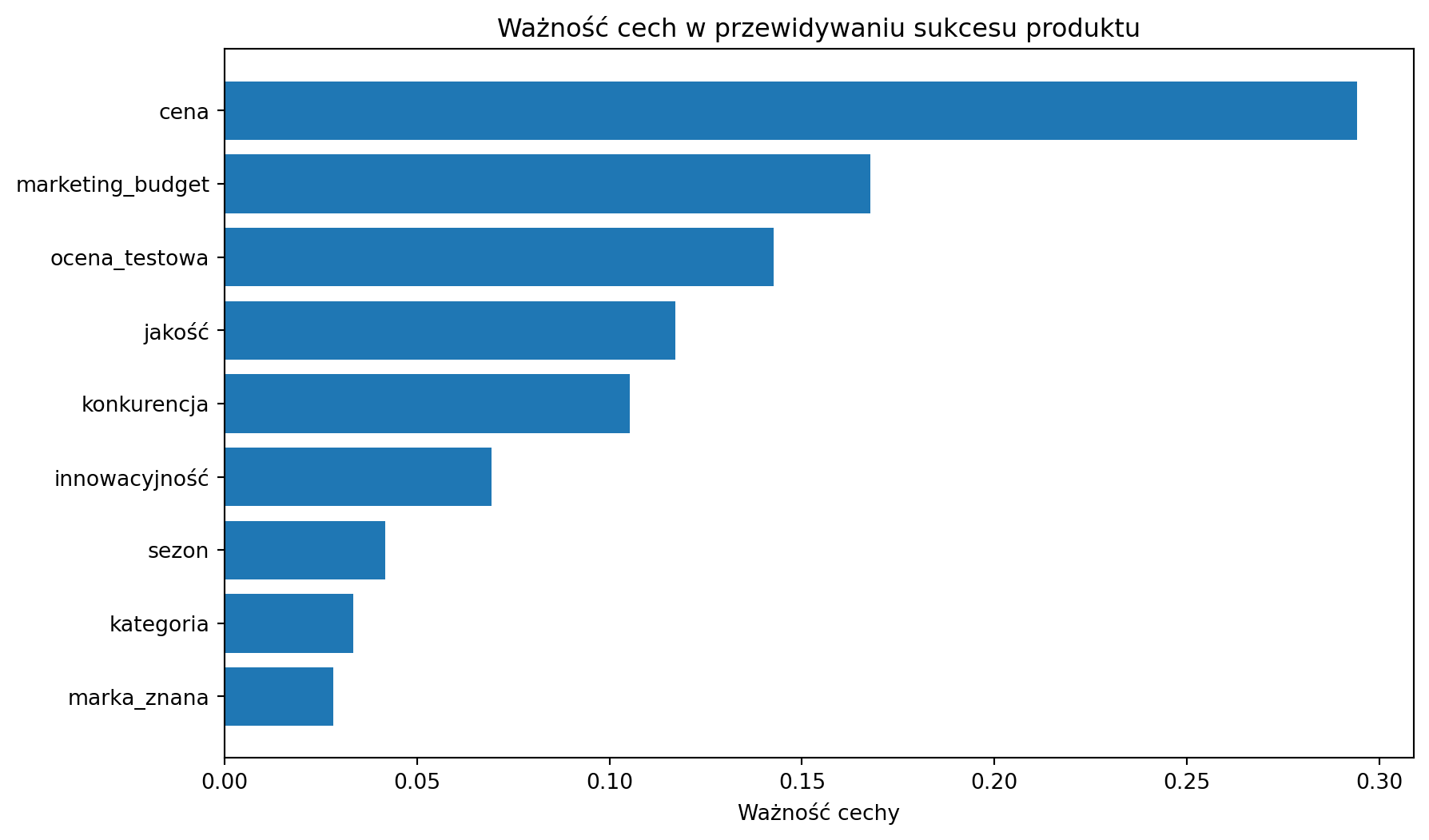
🔍 Random Forest vs Decision Tree - porównanie
from sklearn.tree import DecisionTreeClassifier
# Porównanie z pojedynczym Decision Tree
dt_model = DecisionTreeClassifier(max_depth=10, random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)
dt_accuracy = accuracy_score(y_test, dt_pred)
print("PORÓWNANIE MODELI:")
print(f"Decision Tree: {dt_accuracy:.1%}")
print(f"Random Forest: {accuracy:.1%}")
print(f"Poprawa: +{(accuracy - dt_accuracy)*100:.1f} punktów procentowych")
# Test stabilności - różne random_state
dt_results = []
rf_results = []
for rs in range(10):
# Decision Tree
dt_temp = DecisionTreeClassifier(max_depth=10, random_state=rs)
dt_temp.fit(X_train, y_train)
dt_results.append(accuracy_score(y_test, dt_temp.predict(X_test)))
# Random Forest
rf_temp = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=rs)
rf_temp.fit(X_train, y_train)
rf_results.append(accuracy_score(y_test, rf_temp.predict(X_test)))
print(f"\nSTABILNOŚĆ (10 różnych random_state):")
print(f"Decision Tree rozrzut: {max(dt_results)-min(dt_results):.1%}")
print(f"Random Forest rozrzut: {max(rf_results)-min(rf_results):.1%}")
print("Random Forest jest znacznie bardziej stabilny!")
Pokaż porównanie modeli
PORÓWNANIE MODELI:
Decision Tree: 98.5%
Random Forest: 99.8%
Poprawa: +1.3 punktów procentowych
STABILNOŚĆ (10 różnych random_state):
Decision Tree rozrzut: 1.0%
Random Forest rozrzut: 0.0%
Random Forest jest znacznie bardziej stabilny!🎯 Zastosowania Random Forest
1) E-commerce - rekomendacje produktów
# Przewidywanie czy użytkownik kupi produkt
ecommerce_features = ['historia_zakupów', 'czas_na_stronie', 'kategoria_preferowana',
'cena_produktu', 'oceny_produktu', 'sezon']
# Target: 'kupi_produkt' (tak/nie)
ecommerce_rf = RandomForestClassifier(n_estimators=200)
# Wynik: system rekomendacji uwzględniający kompleksowe zachowania użytkowników2) Finanse - wykrywanie fraudów
# Identyfikacja podejrzanych transakcji
fraud_features = ['kwota', 'godzina', 'lokalizacja', 'typ_karty',
'historia_klienta', 'częstotliwość_transakcji']
# Target: 'fraud' (tak/nie)
fraud_rf = RandomForestClassifier(n_estimators=500, class_weight='balanced')
# Wynik: system antyfaudowy z wysoką dokładnością3) HR - przewidywanie odejść pracowników
# Employee churn prediction
hr_features = ['satisfaction', 'last_evaluation', 'projects', 'salary',
'time_company', 'work_accident', 'promotion']
# Target: 'left_company' (tak/nie)
hr_rf = RandomForestClassifier(n_estimators=300)
# Wynik: wczesne ostrzeżenia przed odejściami kluczowych pracowników⚙️ Tuning parametrów Random Forest
from sklearn.model_selection import GridSearchCV
# Najważniejsze parametry do tuningu
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [5, 10, 15, None],
'min_samples_split': [10, 20, 50],
'min_samples_leaf': [5, 10, 20],
'max_features': ['sqrt', 'log2', None]
}
# Grid search z cross-validation (uwaga: może potrwać!)
print("Rozpoczynam Grid Search - może potrwać kilka minut...")
grid_search = GridSearchCV(
RandomForestClassifier(random_state=42),
param_grid,
cv=3, # redukcja CV dla szybkości
scoring='accuracy',
n_jobs=-1,
verbose=1
)
grid_search.fit(X_train, y_train)
print("Najlepsze parametry:")
print(grid_search.best_params_)
print(f"Najlepsza dokładność CV: {grid_search.best_score_:.1%}")
# Model z najlepszymi parametrami
best_rf = grid_search.best_estimator_
best_accuracy = accuracy_score(y_test, best_rf.predict(X_test))
print(f"Dokładność na test set: {best_accuracy:.1%}")
Pokaż najlepsze parametry
Najlepsze parametry:
{'max_depth': 5, 'max_features': 'sqrt', 'min_samples_leaf': 5, 'min_samples_split': 10, 'n_estimators': 50}
Najlepsza dokładność CV: 99.0%
Dokładność na test set: 99.8%⚠️ Pułapki i rozwiązania
1) Overfitting mimo ensemble
# Problem: za głębokie drzewa mogą nadal prowadzić do overfittingu
overfitted_rf = RandomForestClassifier(
n_estimators=100,
max_depth=None, # bez limitu głębokości!
min_samples_leaf=1 # pozwól na liście z 1 próbką!
)
overfitted_rf.fit(X_train, y_train)
train_acc_over = accuracy_score(y_train, overfitted_rf.predict(X_train))
test_acc_over = accuracy_score(y_test, overfitted_rf.predict(X_test))
print(f"Overfitted Random Forest:")
print(f"Train accuracy: {train_acc_over:.1%}")
print(f"Test accuracy: {test_acc_over:.1%}")
print(f"Różnica: {train_acc_over - test_acc_over:.1%}")
# Rozwiązanie: odpowiednie parametry
balanced_rf = RandomForestClassifier(
n_estimators=100,
max_depth=10, # ogranicz głębokość
min_samples_leaf=10 # wymuś więcej próbek w liściach
)
balanced_rf.fit(X_train, y_train)
train_acc_bal = accuracy_score(y_train, balanced_rf.predict(X_train))
test_acc_bal = accuracy_score(y_test, balanced_rf.predict(X_test))
print(f"\nBalanced Random Forest:")
print(f"Train accuracy: {train_acc_bal:.1%}")
print(f"Test accuracy: {test_acc_bal:.1%}")
print(f"Różnica: {train_acc_bal - test_acc_bal:.1%} - znacznie lepiej!")
Pokaż wyniki overfittingu
Overfitted Random Forest:
Train accuracy: 100.0%
Test accuracy: 99.8%
Różnica: 0.2%
Balanced Random Forest:
Train accuracy: 99.0%
Test accuracy: 99.8%
Różnica: -0.8% - znacznie lepiej!2) Niezbalansowane klasy
# Problem: gdy jedna klasa jest rzadka (np. 5% fraudów, 95% normalnych transakcji)
from sklearn.utils.class_weight import compute_class_weight
# Sprawdź balans klas w naszych danych
print(f"Rozkład klas:")
print(f"Porażka: {(~y_train).sum()} ({(~y_train).mean():.1%})")
print(f"Sukces: {y_train.sum()} ({y_train.mean():.1%})")
# Rozwiązanie 1: class_weight='balanced'
balanced_class_rf = RandomForestClassifier(
n_estimators=100,
class_weight='balanced', # automatyczne ważenie klas
random_state=42
)
balanced_class_rf.fit(X_train, y_train)
# Rozwiązanie 2: bootstrap sampling
balanced_rf = RandomForestClassifier(
n_estimators=100,
max_samples=0.8, # użyj tylko 80% próbek do każdego drzewa
random_state=42
)
balanced_rf.fit(X_train, y_train)
print("Rozwiązania zostały zaimplementowane!")
Pokaż rozkład klas
Rozkład klas:
Porażka: 16 (1.0%)
Sukces: 1584 (99.0%)
Rozwiązania zostały zaimplementowane!🌍 Real-world przypadki użycia
- Finanse: Credit scoring, wykrywanie prania pieniędzy, trading algorytmiczny
- E-commerce: Systemy rekomendacji, dynamic pricing, churn prediction
- Healthcare: Diagnoza medyczna, drug discovery, analiza obrazów medycznych
- Marketing: Customer segmentation, campaign optimization, A/B testing
- Cybersecurity: Intrusion detection, malware classification, anomaly detection
💡 Kiedy używać Random Forest?
✅ UŻYJ GDY:
- Potrzebujesz wysokiej dokładności z interpretowalnym modelem
- Masz mixed features (liczbowe + kategoryczne)
- Dane zawierają missing values (RF radzi sobie z nimi dobrze)
- Chcesz feature importance bez complex feature engineering
- Potrzebujesz stabilnego modelu (mała wariancja)
❌ NIE UŻYWAJ GDY:
- Masz bardzo duże datasety (użyj XGBoost/LightGBM)
- Potrzebujesz bardzo prostego modelu (użyj Decision Tree)
- Target jest continuous i potrzebujesz liniowej interpretacji (użyj Linear Regression)
- Masz bardzo wysokowymiarowe dane (użyj SVM lub Neural Networks)
Następna ściągawka: K-Means Clustering - grupowanie bez etykiet! 🎯